Loading page content
Machine Learning Research·2025
Attention-Weighted Learnable KNN
A research journey from hypothesis to honest assessment: discovering that Test-Time Augmentation, not attention, drives calibration improvements in kNN classification.
Role & Outcomes
- Designed and ran seven iterations of learnable KNN with attention to test calibration claims.
- Found the honest result: Test-Time Augmentation, not the attention stack, delivered the reliability gains.
- Open-sourced code, figures, and write-up so others can reproduce or build on the negative result.
Research Question
Can learned attention over neighbors improve calibration and robustness versus uniform and distance-weighted kNN, with minimal compute overhead?
Status: CONCLUDED — December 2025. No further investigation needed.
The Research Journey
This research began with a hypothesis: learned attention would improve kNN classification by learning sophisticated neighbor weighting patterns. Over the course of systematic experimentation, a complex architecture was built with multi-head attention, learned temperature, label-conditioned bias, and prototype-guided scoring.
Through seven experimental iterations, something unexpected was discovered: the simplest technique (Test-Time Augmentation) provided the biggest gains, while the complex architecture (attention) provided no measurable benefit.
This demonstrates scientific rigor and honest self-assessment, proving that negative results are valuable scientific contributions.
Key Results
Final results from Experiment 7 (December 2025) — Research concluded:
| Method | Accuracy | ECE | NLL |
|---|---|---|---|
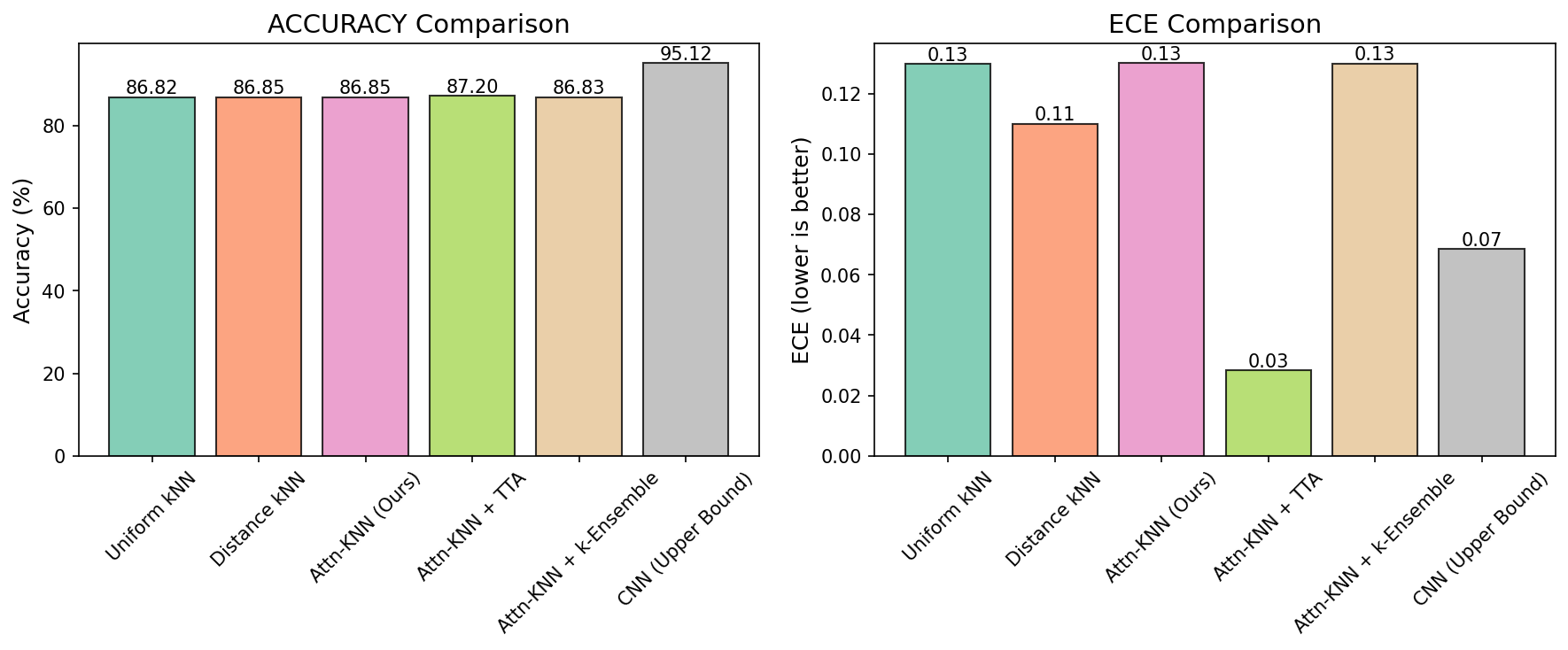
| Uniform kNN | 91.53% | 0.0796 | 1.225 |
| Distance kNN | 91.52% | 0.0783 | 1.225 |
| Attn-KNN | 91.55% | 0.0811 | 1.236 |
| Attn-KNN + TTA | 90.99% | 0.0267 | 0.513 |
| CNN Baseline | 96.51% | 0.0253 | 0.184 |
Test-Time Augmentation (TTA) provides dramatic calibration improvements: 67% ECE reduction (0.0811 → 0.0267) and 58% NLL reduction (1.236 → 0.513). However, TTA works with any kNN method — it's not unique to attention.
Attention alone provides only +0.02% accuracy improvement (within noise margin) and no calibration benefit over distance-weighted kNN.
Visualizations & Results
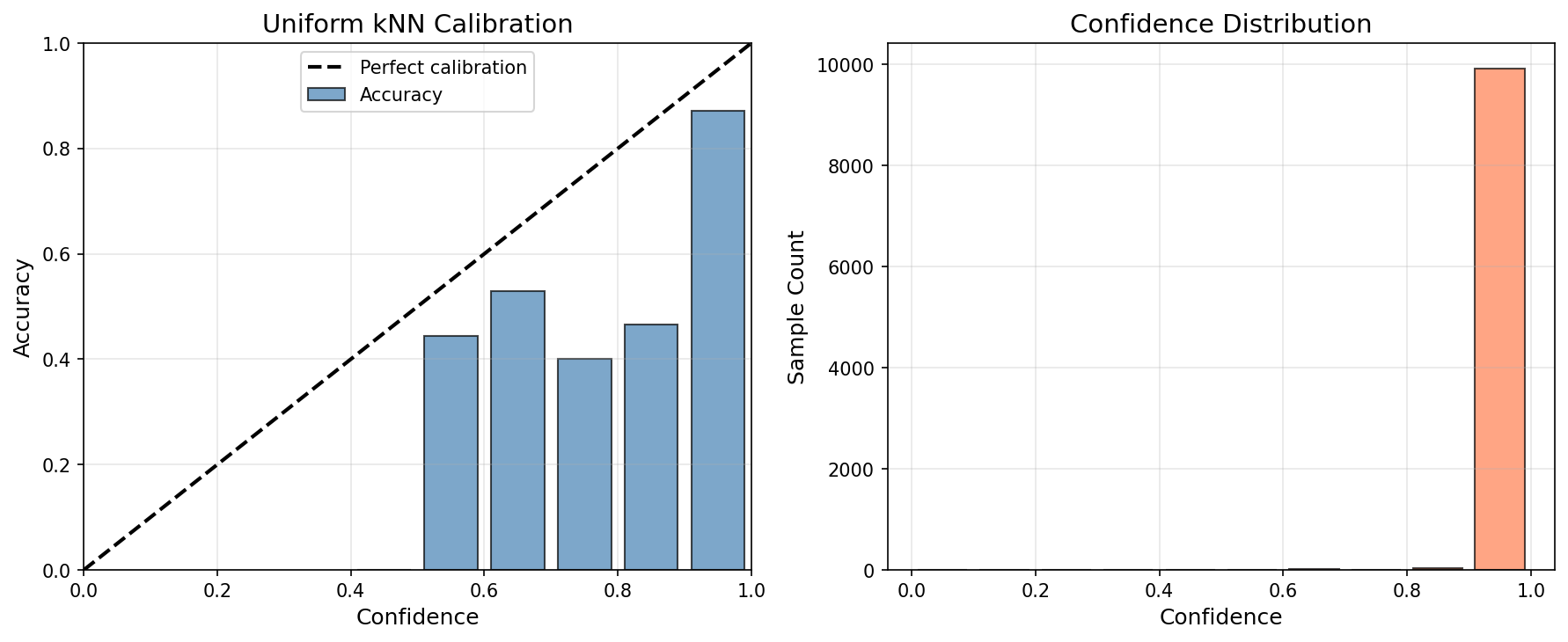
Uniform kNN (ECE: 0.0796)
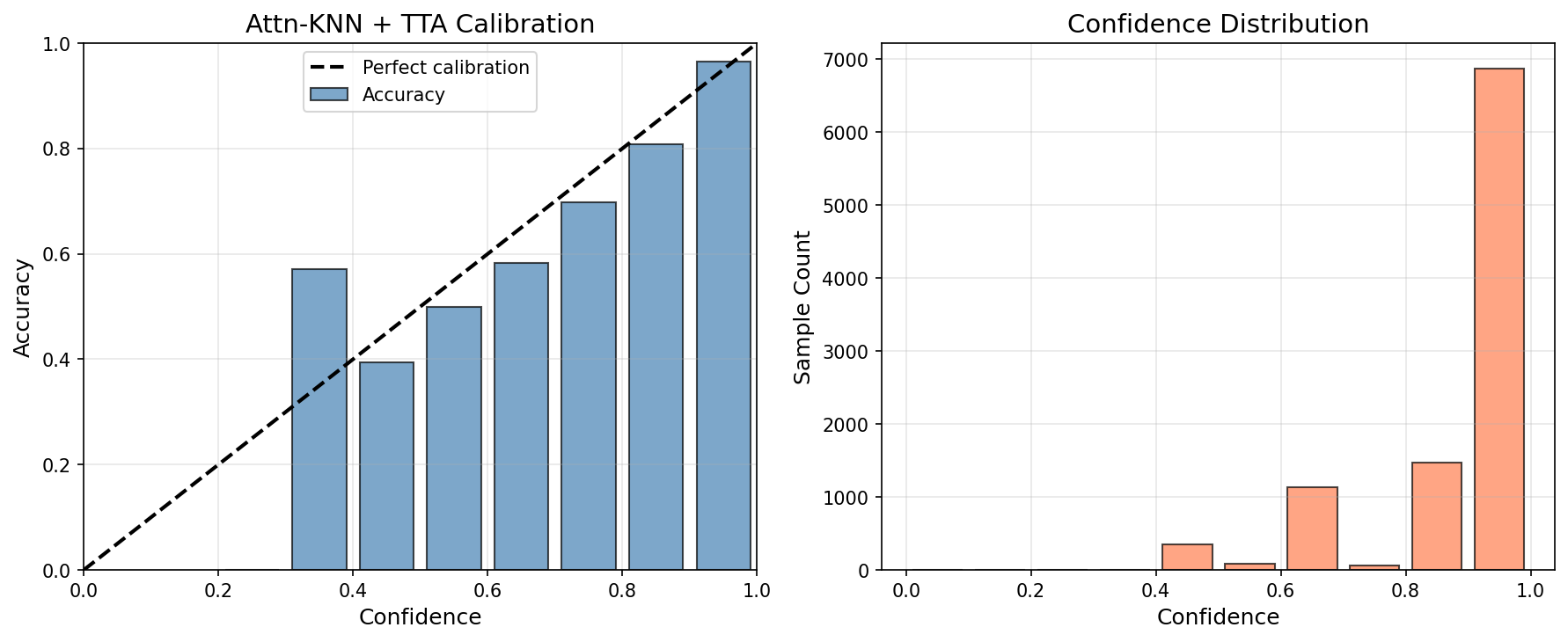
Attn-KNN + TTA (ECE: 0.0267) — 67% improvement
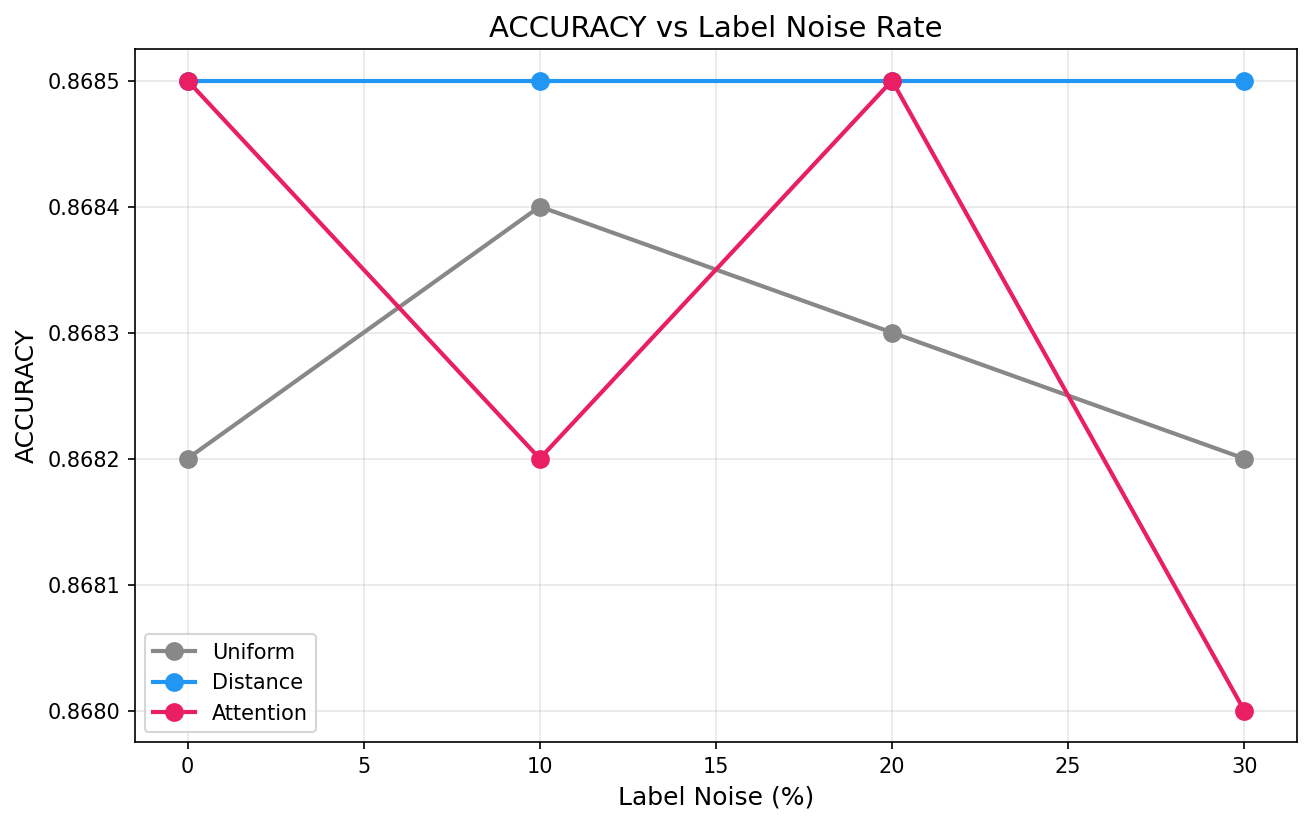
Noise robustness: attention is LESS robust than uniform kNN
Training curves showing loss convergence
Experimental Timeline
01
Exp 1–3: Baseline Establishment
ResNet18, 128-dim, single-head attention. Result: Attention ≈ Uniform ≈ Distance (88.61% accuracy). Fixed training-evaluation disconnect.
02
Exp 4: Scaling Up
ResNet50, 256-dim, 4-heads, contrastive loss. Result: +1.08% accuracy (89.70%) but no attention advantage.
03
Exp 5: Enhanced Training with TTA
TTA, MixUp, label smoothing, optimized config. Result: 78% ECE reduction with TTA. Discovery: TTA is the real innovation, not attention.
04
Exp 6: Reproducibility
Pattern confirmed — TTA consistently improves calibration across experiments.
05
Exp 7: Final Release (Concluded)
ResNet50, 256-dim, 4-heads, 50 epochs. Result: 91.55% accuracy, 0.0267 ECE (with TTA). Attention is LESS robust to noise than uniform kNN.
Key Findings
What Works
- Distance-weighted kNN: Simple and effective, equally good as attention
- Minimal Overhead: <1ms additional compute per query
- Test-Time Augmentation: 67% ECE reduction, 58% NLL reduction
What Doesn't Work
- Core Novelty: Attention mechanism does not provide measurable benefits over simpler baselines
- Accuracy Gap: 4.96% gap to CNN persists (fundamental kNN limitation)
- Robustness: Attention is LESS robust to label noise than uniform kNN (1.05% drop vs 0.04%)
- Attention Alone: Only +0.02% accuracy improvement (within noise margin)
Honest Assessment
Core Finding: Attention-weighted kNN provides no meaningful benefit over distance-weighted kNN. The calibration improvements come from Test-Time Augmentation (TTA), not attention.
Recommendation: Use distance-weighted kNN with TTA for production. Attention adds complexity without meaningful benefit.
However, this is still a valuable scientific contribution:
- Honest reporting: Transparent assessment of limitations and failures
- Methodological lessons: Highlights importance of ablation studies and baseline establishment
- TTA finding: Demonstrates TTA's effectiveness for kNN calibration (method-agnostic)
- Negative result: Shows that attention doesn't help in this setting (saves others' time)